Semantically Structured Instruction Representations for Reward-Free Policy Adaptation
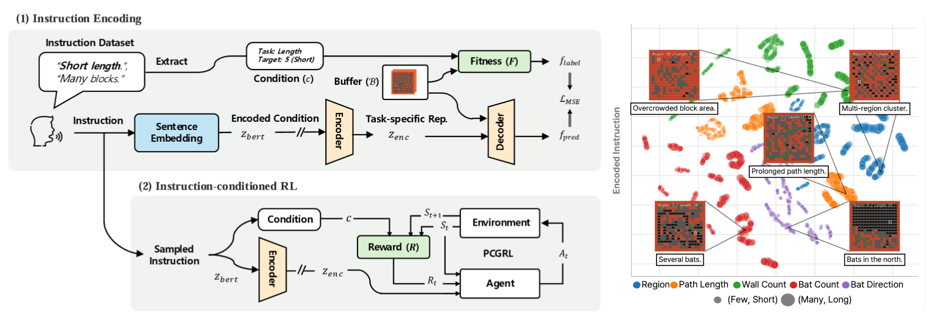

Standard RL policies are coupled to a fixed training objective: adapting to a new goal requires modifying the reward function and retraining from scratch, with no mechanism for receiving human instruction at deployment time. We address this by conditioning the policy on a semantically structured instruction embedding— encoded from a natural-language specification and injected directly into the policy network—so that varying the instruction alone continuously steers behavior at inference time, without any gradient update [1].
The approach extends naturally to the multi-objective setting. Rather than collapsing competing objectives into a scalar, we learn a disentangled representation that encourages each objective dimension to occupy a separable subspace. The policy can then traverse trade-offs across conflicting constraints by interpolating within the instruction space— continuously navigating the behavioral specification without retraining for individual configurations [2].
Resolving Behavioral Underspecification via Tri-Modal Contrastive Grounding

A natural-language prompt is consistent with many distinct output distributions—the same instruction can reasonably describe very different behaviors, leaving the policy underspecified. We address this through a tri-modal contrastive grounding framework that jointly embeds three signal types— natural-language instructions, spatial layout observations, and output trajectories—into a unified metric space. The contrastive objective pulls together representations from different modalities that correspond to the same behavioral target, while pushing apart representations of distinct targets.
The policy accepts any available subset of modalities as input, allowing flexible deployment under partial observability. Combining text with spatial observations resolves much of the ambiguity that language alone cannot eliminate, reducing output variance in our evaluations. Human preference studies confirm that the grounded policy produces behavior that more faithfully matches the specified intent than single-modality baselines [3].
A Unified Latent Space for Language-Guided Recombination Across Structurally Distinct Environments
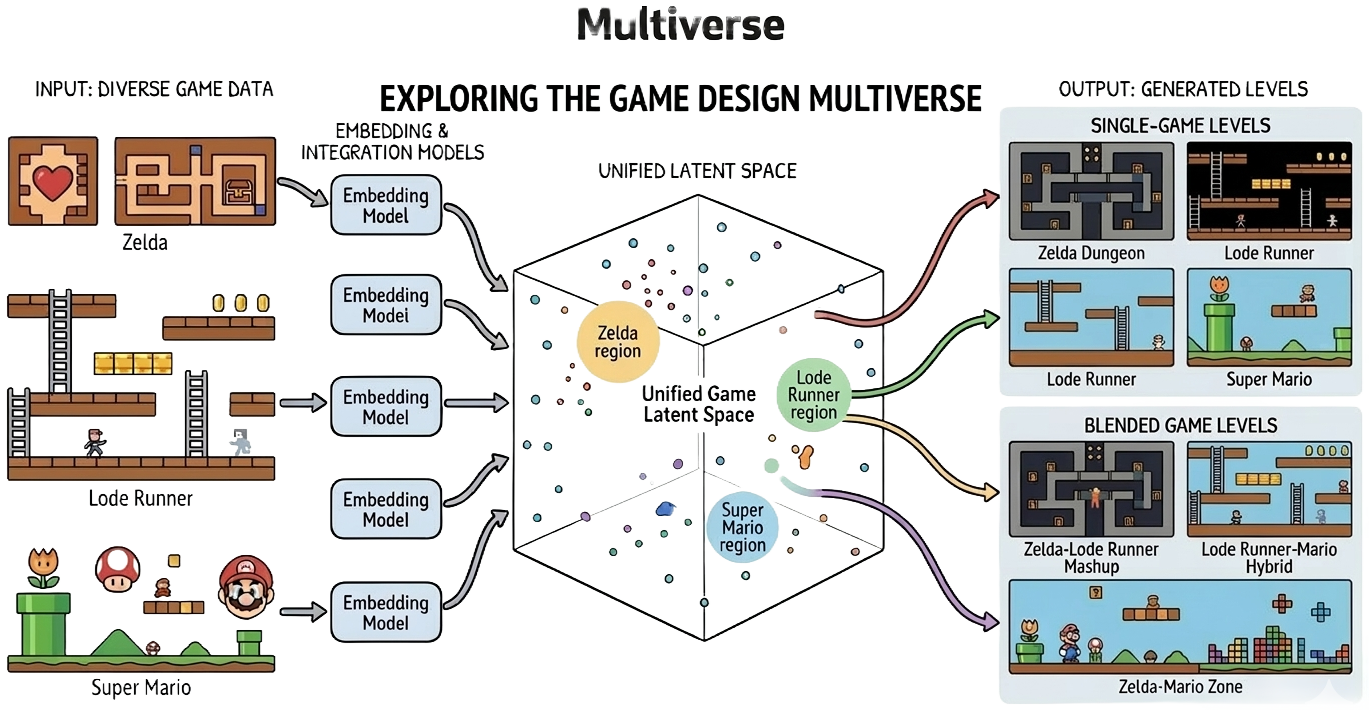
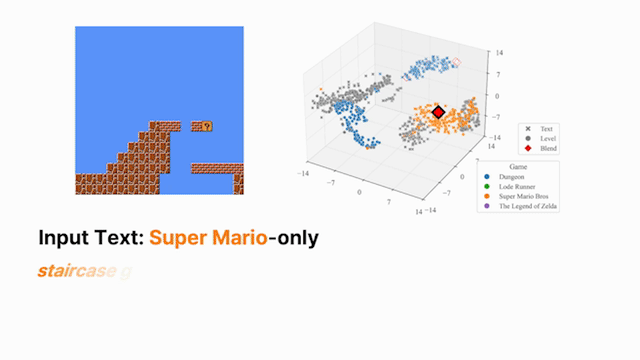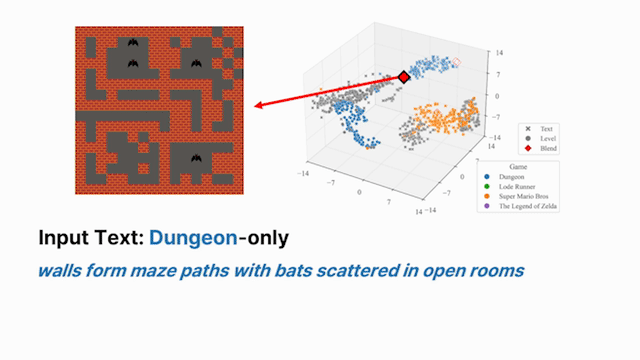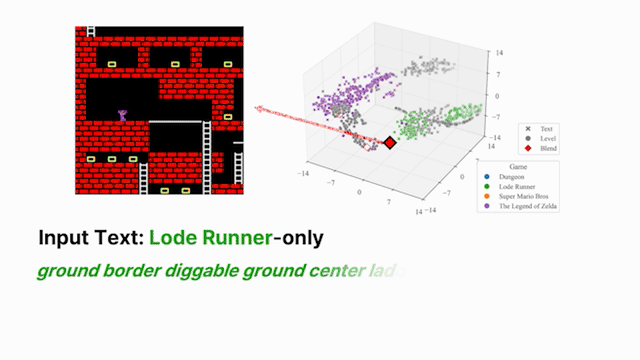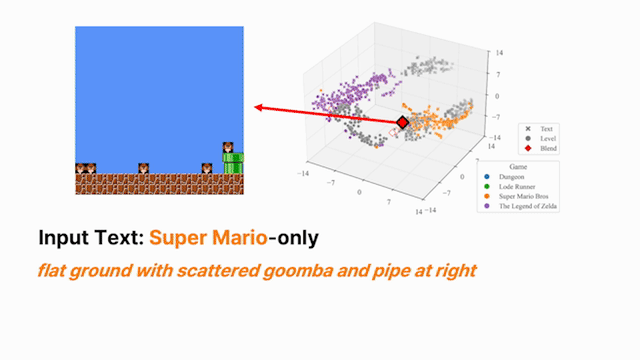
Thrusts 1–2 operate within a single environment. The harder question is whether a shared representation can capture structural regularities across multiple distinct environments and make those regularities accessible for reuse. We train a single encoder jointly across structurally distinct domains under a cross-environment alignment objective that draws together latent representations of behaviorally equivalent targets, while preserving environment-specific structure where needed. The result is a unified embedding space that supports transfer: knowledge acquired in one environment can be directly accessed and reused in another without fine-tuning.
A language instruction then parameterizes soft interpolation within this shared space, producing outputs that compositionally blend characteristics from distinct source environments—enabling zero-shot recombination of behaviors not seen in any single training domain [4]. This compositional structure is the foundation for the broader agenda: extending the same shared encoder to control policies could allow language-guided latent interpolation to directly produce behavioral blends across tasks, potentially enabling open-ended adaptation to novel task combinations at inference time.